0.概述
结构体(Struct):存放一组不同类型的数据的数据结构。
数组(Array):存放一组相同类型的数据的数据结构。
结构体和int,char,指针等基础数据类型一样,也是一种数据类型。格式定义如下:
struct 结构体名{
成员类型1 成员名1;
成员类型2 成员名2;
}实例1,实例2;
结构体的成员(Member)可以为任意类型,如int,char,指针,甚至结构体类型。
结构体可以配合结构体数组、普通指针、函数指针、以及自身嵌套的使用方法,实现复杂数据结构,以及面向对象的代码风格。
1.结构体声明
声明是告诉编译器某个数据结构的定义。一般在头文件对结构体、函数等类型声明。声明过程不分配内存。
一个结构体类型的声明:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
};
注意:
1.结构体声明类似于函数声明,是一个语句,末尾加;
2.结构体声明只声明了类型,不实例化变量,因此不分配内存。
3.结构体成员的变量只在实例结构体才分配内存。
2.结构体实例
2.1基础方法
结构体变量是结构体类型的实例,实例化就是在内存分配一个结构体类型的变量空间。
方法一:先声明结构体类型stu,再实例变量stu1,stu2。
该方法结构体类型声明和实例化分离。声明一次,到处实例化。注意实例变量要带struct关键字。
struct stu stu1, stu2;
方法二:声明的时候也实例变量stu1,stu2。
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1, stu2;
方法三:不声明接头体名,直接实例变量。
适用于只需要 stu1、stu2两个变量,后面不需要再使用结构体名定义其他变量的情况
struct{ //没有写stu
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1, stu2;
2.2重定义方法
结构体类型通常配合typedef重定义后声明。
声明一次,到处实例化。不需要带struct关键字。
typedef struct stu{ //stu可省略
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}stu_t, *stu_p; //声明stu_t为stu类型,stu_p为stu类型的指针
实例变量:
stu_t stu1,stu2; //实例两个stu结构体变量
stu_p *stu1_p, *stu2_p; //实例两个指向stu结构体指针
stu1_p = &stu1; //指向实例stu1
stu2_p = &stu2; //指向实例stu2
3.结构体初始化
初始化=赋初始值。
结构体的实例只分配了内存,其成员的值要手动赋值后才能确定。否则直接拿来用会得到不确定的值(取决于分配到的内存原本的值)。
以重定义的结构体类型stu_t为例,实例变量时顺便初始化所有成员为0:
stu_t stu1,stu2 = {0};
有的编译器可能要求这种写法:
stu_t stu1,stu2 = {{0}};
如果各成员有默认初始值,初始化如下:
stu_t stu1, stu2 = { "Tom", 9527, 18, 'A', 136.5 };
4.结构体的赋值
结构体赋值是对结构体变量内的成员赋值。
两种方式访问成员:
结构体变量.成员名;
stu1.name = 'Tom';
结构体指针->成员名
stu1_p->name = 'Tom';
这两种方法的选择取决于使用情况。如果结构体作为参数在函数之间频繁传递和赋值,建议使用传指针,而不是传结构体变量,这样减少函数为结构体频繁分配局部内存,但要注意结构体已被释放,形成空指针的判断。
注意是对实例的成员赋值(已分配内存),而不能对结构体类型的成员赋值(只是个标签)。例如如下操作是错误的:
stu_t.name = "Tom" //错,stu_t是类型
stu1_p = &stu_t //错,stu_t没地址
可以对结构体类型进行sizeof操作,而不需要分配内存。
sizeof(stu_t); //获取结构体(将)占用的内存空间
5.结构体的内存分配
理论上结构体的内存占用是成员占用的和。各成员在内存中连续存储的,和数组非常类似,例如结构体变量 stu1、stu2的内存分布如下,共占用 4+4+4+1+4=17字节。
但实际上,编译器会遵循内存对齐规则。实际内存占用大于各成员占用的和。如下图,stu1、stu2 其实占用了 17+3=20 字节
5.1内存对齐概述
1.CPU怎么访问内存中的数据最高效?
答:用最少的访问次数,获取该数据所在的内存空间的值。
2.怎么做到对某类型数据的最少访问?
答:编译器设置数据的存放地址的单位为数据占用空间的长度,CPU以数据长度为单位查询偏移地址,找到数据空间首地址后,根据数据类型取出其占用空间大小的数据。
如int数据,就存放在以4字节为单位的偏移地址,如0,4,8…,CPU取数据就按0,4,8…的地址查询,找到该数据地址后取4字节。这样做到一次性访问获取int数据。如果CPU按单字节访问int,就要查询4次,如int首字节地址为0x00001024, CPU要分4次查询0x00001024~0x00001027才能得到一个int。
3.对于结构体,包含多种数据类型,怎么对齐?
答:各成员按各自的类型对齐,即对于成员来说不存在结构体的概念,它认为它就是基本的数据类型int、char、指针等。
5.2结构体与内存对齐
结构体是不同类型数据的集合,因此内存对齐问题就特别突出。一个例子:
#include "stdio.h"
typedef struct {
int a;
double b;
char c;
}A;
typedef struct {
int a;
char b;
double c;
}B;
int main()
{
printf("sizeof A: %d, sizeof B: %d\n", sizeof(A), sizeof(B));
}
A和B的内存占用:A=24字节,B=16字节。
结构体内存对齐的计算规则:
1.默认首地址已对齐(或认为是0地址)
2.各成员按自己的类型对齐
3.整个结构体分配的空间是期中最大成员占用空间的整数倍
对于A:
int a占用4字节,地址byte[03]15]
double b占8字节,起始地址必须是8的倍数,占用byte[7
char c占1字节,因此占byte[16]
目前共占用17字节。编译器会按照规则3,将byte[17~13]也分配给结构体,因此最终结构体占用38=24字节。
对于B, int a和char b加起来都不够8字节,double c再占用8字节,共占用28=16字节。
因此结构体的内存分配=各成员按类型对齐+总空间是最大成员空间的倍数
注意,结构体不仅成员间要对齐,最后一个成员后面的空余空间可能也分配给结构体。
查看下面的测试程序:
typedef struct {
int a;
double b;
char c;
char d; //d作为成员
}C;
typedef struct {
int a;
double b;
char c;
struct { //d作为嵌套结构体的成员
char d;
};
}D;
printf("sizeof C: %d, sizeof D: %d\n", sizeof(C), sizeof(D));
C和D的内存占用:
新增的char d作为C的成员被分配在第三个8byte区域的第二个字节(byte[17]),嵌套的结构体并不从第四个8byte开始分配,它占用空间还是byte[17]。可见编译器对结构体内存分配不区分成员类型,只根据成员大小来处理。
6.联合、位域、枚举
这几种数据结构体和结构体相关联,通常混合使用。
6.1联合
联合(Union)也称共用体,和结构体的区别:
结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
声明格式:
union 共用体名{
成员列表
};
共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
联合的一个示例:
#include <stdio.h>
union data{
int n;
char ch;
short m;
};
int main(){
union data a;
printf("%d, %d\n", sizeof(a), sizeof(union data) );
a.n = 0x40;
printf("%X, %c, %hX\n", a.n, a.ch, a.m);
a.ch = '9';
printf("%X, %c, %hX\n", a.n, a.ch, a.m);
a.m = 0x2059;
printf("%X, %c, %hX\n", a.n, a.ch, a.m);
a.n = 0x3E25AD54;
printf("%X, %c, %hX\n", a.n, a.ch, a.m);
return 0;
}
输出:
4, 4
40, @, 40
39, 9, 39
2059, Y, 2059
3E25AD54, T, AD54
在内存中数据分布如下(以大端,低字节存高位为例)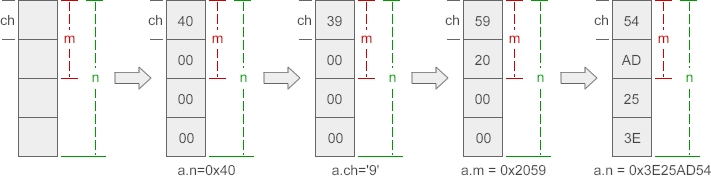
可见数据会相互覆盖,联合可以理解为分时复用的结构体,其空间占用定长,为最大的成员长度,在不同时间,值的含义不同。
6.2位域
有的结构体成员在存储时并不占用一个完整的字节,只需要按二进制位为单位分配空间即可。可以指定该成员所占用的二进制位数(Bit),这就是位域。
#include "stdio.h"
struct {
unsigned char a; //a占完整的8bit
unsigned char b: 2; //b占2bit
unsigned char c: 6; //C占6bit
}bs;
int main()
{
printf("sizeof bs: %d\n", sizeof(bs));
}
输出2字节,可见b和c刚好拼成一个unsigned char(8 bit):
位域将结构体成员占用的空间从基本数据类型为单位,变成了以二进制位为单位,是更精细的结构体内存分配。
位域不能超过对应基本类型的二进制位数。
6.3枚举
枚举可以理解为计数宏的结构体。
#include <stdio.h>
int main(){
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } day;
scanf("%d", &day);
switch(day){
case Mon: puts("Monday"); break;
case Tues: puts("Tuesday"); break;
case Wed: puts("Wednesday"); break;
case Thurs: puts("Thursday"); break;
case Fri: puts("Friday"); break;
case Sat: puts("Saturday"); break;
case Sun: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}
枚举值默认从0开始,往后逐个加 1(递增);如果第一个成员赋值,从那个成员值往后递增。也就是说,week中的 Mon、Tues …… Sun 对应的值分别为 1、2… 7。
宏在编译的预处理阶段将名字替换成对应的值,而枚举在编译阶段将名字替换成对应的值。在编译过程中,Mon、Tues、Wed 名字都被替换成了对应的数字。这意味着Mon、Tues、Wed 等都不是变量,不占用数据区(常量区、全局数据区、栈区和堆区)的内存,而是被编译到指令里面,放到代码区,所以不能用&取得它们的地址。这就是枚举的本质。
枚举类型实例的内存占用通常=int类型占用=4字节。
7.结构体常见用法
7.1结构体数组
结构体数组是将多个同类型结构体按数组的方式存储,其成员访问方式为:先访问数组元素,再访问结构体成员。
结构体数组本质还是数组,但数组成员是结构体,结构体内可以包含各种类型的成员。
一个Linux NandFlash驱动的结构体数组如下:
static struct mtd_partition s3c_nand_parts[] = {
[0] = {
.name = "bootloader",
.size = 0x00040000,
.offset = 0,
},
[1] = {
.name = "params",
.offset = MTDPART_OFS_APPEND,
.size = 0x00020000,
},
[2] = {
.name = "kernel",
.offset = MTDPART_OFS_APPEND,
.size = 0x00200000,
},
[3] = {
.name = "root",
.offset = MTDPART_OFS_APPEND,
.size = MTDPART_SIZ_FULL,
}
};
该数组名为s3c_nand_parts,成员为mtd_partition结构体,包含分区名,分区大小和分区偏移地址。每个结构体成员分别初始化赋值。注意结构体数组实例没写结构体名,只有数组下标[],结构体成员没写结构体名,只有.符号。这是Linux kernel常见的精简写法。
访问一个结构体数组的成员:
s3c_nand_parts[0].name = "bootloader_2"
结构体数组的内存占用=数组成员数*单个结构体内存占用。
7.2结构体指针
结构体指针本质是指针变量,其值是结构体的地址。
前面结构体重定义一节已经定义和初始化过结构体指针,需要注意的是,结构体指针的初始化值来源于结构体实例,结构体类型名只是标签,不代表结构体地址,注意和”数组名=数组地址“区分。
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1, stu2;
struct stu *stu_p = stu; //错,stu只是符号,不占内存
struct stu *stu_p = &stu1; //对,stu1是结构体实例,占内存 //对,stu1是stu实例变量,有内存占用
结构体指针的常见用途:malloc分配结构体空间
stu_p =(stu_t *)malloc(sizeof(stu_t)); //分配结构体空间,返回地址给结构体指针
结构体指针最重要的用途:函数传参
结构体变量作为函数参数时传递的是整个结构体内存空间,也就是所有成员空间,而不是像数组一样被编译器转换成一个指针。如果结构体成员较多,传送的时间和空间开销会很大,影响程序的运行效率。所以最好的办法就是使用结构体指针,这时由实参传向形参的只是一个地址,非常快速。
7.2结构体嵌套
结构体嵌套是结构体的成员也是结构体。有两种情况:
1.成员是其他类型的结构体
2.成员是同类型的结构体
7.2.1.嵌套其他类型
在协议开发中,一个命令的数据可以用结构体来表达,在命令的内部又分为很多个数据域,每个数据域又用结构体来表达,因此需要结构体嵌套。对于同一块数据,根据命令的不同,解析为不同的结构体,因此存在多类命令公用一块数据域的情况,因此需要联合(Union)。以NVMe协议为例,结构体嵌套和联合一起使用的例子:
typedef struct //nvme命令结构体
{
union //命令中dword10空间的联合
{
u32 command_dw10;
struct
{
u32 cntid:16; //16 bit位域
u32 resv1:8; //8 bit位域
u32 cns:8; //8 bit位域
}identify; //当命令为identify时
struct
{
u32 save:1;
u32 resv1:20;
u32 select:3;
u32 feature_identifier:8;
}get_features; //当命令为get_featuresy时
struct
{
u32 queue_size:16;
u32 queue_identifier:16;
}io_queue_create_delete_dw10;
...
};
union //命令中dword11空间的联合
{
u32 command_dw11;
struct
{
u32 completion:16;
u32 submission:16;
}number_of_queues;
struct
{
u32 interrupt_vector:16;
u32 resv1:14;
u32 interrupt_enabled:1;
u32 physically_contiguous:1;
}create_io_completion_queue_dw11;
...
};
}command_t, *command_p;
该例子结合了结构体、联合、位域。对每个nvme命令,多个联合并存在结构体command_t实例里,每个联合长度为一个dword(4字节),分别表示dword0~15中的一个。对于dword内部,根据解析到命令的不同,作为不同含义处理,如解析为identify就按identify的结构体读写成员,如解析为get_features则按get_features的结构体读写成员。在结构体内部,用位域更精细控制这个dword内各bit的含义。
7.2.2嵌套自身类型
结构体嵌套自身类型的典型应用:链表数据结构体
typedef struct ListNode {
DataType data; // 节点数据
struct ListNode *next; // 指向下一个结点的指针
} ListNode_t;
这个结构体有两个成员:DataType类型的数据,和指向 struct ListNode类型(=ListNode_t类型)的实例的指针。有多个ListNode_t类型的结构体被实例化且依次指向后续节点后,可以依次node1->next->next…->data访问链表中的节点数据。
注意:结构体体能嵌套自身类型的指针,而不能嵌套自身类型的实例。因为指针分配内存是定长(通常4字节),而循环嵌套结构体变量是无穷的。以下写法是错的
typedef struct ListNode {
DataType data;
struct ListNode next; // 错,嵌套的是实例
} ListNode_t;
8.结构体高级用法:面向对象
8.1函数指针
程序中定义的函数,在编译时会为这个函数代码分配一段存储空间,这段存储空间的首地址称为这个函数的入口地址。函数名表示的就是这个地址的值。可以定义一个指针变量来存放函数的入口地址,这个指针变量就叫作函数指针变量,简称函数指针。
这段话什么意思?
1.函数名=函数入口地址
2.可以用指针变量的值取代函数名,函数的调用和该指针变量的调用等价
3.可以把这个指针变量当参数传递给别的函数,也可以把这个指针变量作为结构体的成员,总之,一切指针能做的,函数指针都能做。
函数指针的定义:
返回值 函数入口地址(入参1的类型,入参2的类型,...)
int (*p)(int, int); //p为函数指针,*p为入口地址
定义了一个指针变量 p,该指针变量可以指向返回值类型为 int 型,且有两个整型参数的函数。p 的类型为 int(*)(int,int)
函数指针的初始化:
int Func(int x); /*声明一个函数,包含入参名*/
int (*p) (int); /*声明一个函数指针,只有入参类型*/
p = Func; /*将Func函数的入口地址赋给指针变量p*/
函数指针作为结构体成员的调用如下
struct{
int (* func)(int);
}stu1, *stu1_p; //分配两个结构体实例:stu1结构体和指针stu1_p
stu1.func(10); //通过结构体调用函数指针
stu1_p->func(10); //通过结构体指针调用函数指针
8.2回调函数
回调函数(Callback)就是一个通过函数指针调用的函数。把函数指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由函数的实现方直接调用,而是在特定的事件或条件发生时,由把它当参数的那个函数调用的,用于对该事件或条件进行响应。
回调的两个特点:
1.函数=参数。函数A指针当参数传递B
2.异步。特定时间发生时,B才调用A指针指向的函数
8.3结构体与面向对象
当函数指针作为结构体的成员,可以通过结构体实例调用成员函数,此时可以实现类似其他语言中“类”或“接口”的概念:
结构体声明=类声明=接口声明
结构体的函数指针成员=类方法=接口函数
结构体实例调用函数指针成员=类实例调用方法=接口的实现
这种设计思想在Linux内核和驱动框架中很常用。以字符设备驱动为例:
字符设备驱动顶层框架将所有字符操作函数作为接口在结构体file_operations中定义,在底层具体的设备驱动中实现file_operations的方法。底层驱动实例化file_operations结构体(分配内存),将各种操作的具体实现函数赋值给接口定义的函数,然后上报(注册)该file_operations实例给顶层驱动框架,顶层驱动框架接收到应用层的系统调用请求时,回调已注册的file_operations实例的函数。
上层驱动框架定义的字符文件操作接口如下,这些open、read、write作为文件操作的方法供应用层调用。
struct file_operations { //字符文件操作的接口定义
struct module *owner; //结构体指针
ssize_t(*read) (struct file *, char __user *, size_t, loff_t *); //函数指针read
ssize_t(*write) (struct file *, const char __user *, size_t, loff_t *); //函数指针write
int (*open) (struct inode *, struct file *); //函数指针open
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long); //函数指针ioctl
...
};
而这些方法具体实现(内部做什么)是由底层驱动代码实现:
static int my_drv_open(struct inode *inode, struct file *file)
{
//硬件寄存器操作A...
return 0;
}
static ssize_t my_drv_write(struct file *file, const char __user *buf, size_t count, loff_t * ppos)
{
//硬件寄存器操作B...
return 0;
}
那么这些实现怎么关联接口:在底层驱动分配结构体实例,初始化函数指针为实现函数
static struct file_operations my_drv_fops = {
.owner = THIS_MODULE,
.open = my_drv_open, //open接口由my_drv_open函数实现
.write = my_drv_write, //write接口由my_drv_write函数实现
};
关联完了,上层驱动怎么调用:结构体指针传参+回调
my_drv_fops是file_operations的实例,上报给上层驱动,上层驱动有它自己的字符设备结构体cdev,取出my_drv_fops实例的.结构体指针fops的值,赋给cdev实例内的ops指针。之后它就能用ops调用my_drv_open、my_drv_write函数。
//注册结构体
cdev->owner = fops->owner;
cdev->ops = fops;
//回调.open方法
cdev->ops->open(inode,file);
由于my_drv_write是值,open才是结构体成员,因此调用的时候看上去调用的是open函数,本质上执行的还是my_drv_write的流程。函数指针的回调能将接口名暴露,方法名隐藏。因此底层实现的函数名和上层驱动的调用函数名不相关,上层永远都可以用.open .read .write这些接口调用底层驱动,而底层函数可以随便改名(不能改入参出参类型,否则函数指针类型变了),这种特性都是函数指针决定的。
对于应用程序,是调用上层驱动提供的系统调用接口,还是如.open .read .write等接口。Linux驱动将设备抽象成了文件,驱动程序实现了文件的各种方法,所以对应用程序,打开文件=打开设备,调用文件对应的接口=调用设备驱动提供的接口。
fd = open("/dev/xyz", O_RDWR); //打开文件(设备)
read(fd, &val, 1); //读fd文件(设备)的值到val变量
除了C语言,在golang中也有类似的结构体+函数指针实现的面向对象方法。
NOTE:关于结构体中的函数指针写法易错点:
不包含变量名,只能使用基本类型
#一个结构体
typedef stru{ //定义结构体名
int a;
char b;
}stru_t, *stru_p; //重定义结构体变量和指针
#普通函数声明
int func(int a, stru_p p); //参数写类型且写值,可以使用typedef后的结构体指针类型
#函数指针声明
int (*func)(int, struct stru *); //参数只写类型不写参数,只能使用C基本类型,不能使用typedef后的类型,只能写struct stru *类型
函数指针声明使用typedef后的类型名,编译器不认识,产生syntax error。