1.简介
Tinyhttpd是一个C + CGI实现的简单http server,适合初学者学习。代码许可协议:GPL,copyright 1999, by J. David Blackstone.
本文对Tinyhttp稍作注释和改动,验证并理解其主要流程, 本文源码:
Github: cursorhu/myTinyHttpd
2.背景知识
TCP套接字的通信流程
网络协议栈的核心是TCP/IP协议,HTTP本质上是对TCP的应用层封装,要理解HTTP服务程序,首先要理解TCP层的通信机制,在Linux环境中TCP采用socket接口通信,流程如下图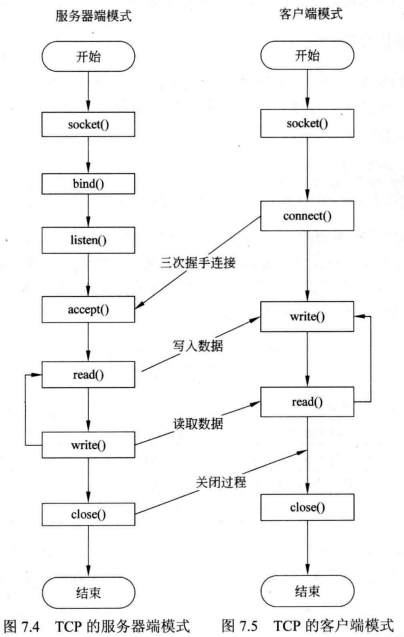
关于Linux网络编程相关知识,参考《Linux网络编程-第二版》
TinyHttpd实现服务端的流程。
HTTP的请求方式
参考:
浅谈HTTP中GET、POST用法以及它们的区别
99%的人都理解错了HTTP中GET与POST的区别
理解以下几点:
- GET,POST,PUT,DELETE是http层对数据操作的封装,底层本质还是TCP的read/write过程
- http server处理请求的基本流程:读取-拆解-处理-封装-回写,拆解和封装的就是http层的请求和数据格式,处理是指TCP层能理解的数据。就像快递退货时的流程:取件-拆包-查看-装包-寄出
CGI的时代背景
参考:CGI是什么
- CGI是2000年的web接口标准,后端部署perl-CGI脚本,连接server处理程序和web客户端
- CGI目前还应用在嵌入式web等C-based环境,这个和当前web主流的Java Spring + Vue(JS)是完全不同的应用场景,所以CGI技术本身并无过时一说。
3.调试httpd
部署httpd服务
Aliyun CentOS环境,运行如下deploy.sh:
#!/bin/bash
chmod +x htdocs/*.cgi
yum install -y perl perl-CGI
make clean && make
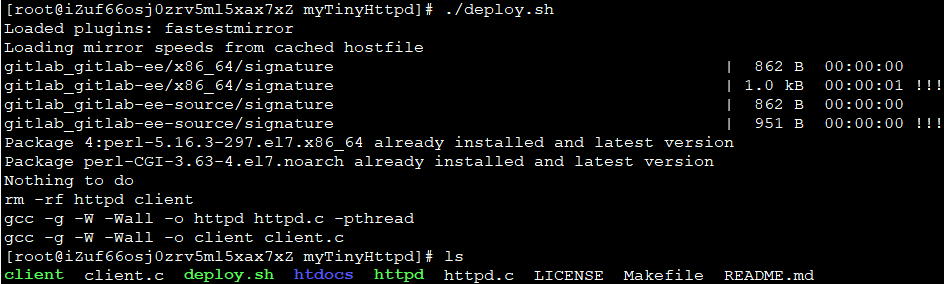
浏览器访问httpd
服务端直接运行httpd,会分配随机可用端口,本地chrome浏览器访问该服务所在的ip:端口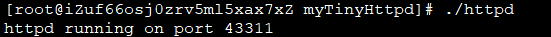
这里ip即为httpd所在主机ip,默认访问资源是htdocs/index.html,原因可见httpd.c的http Get请求解析url的处理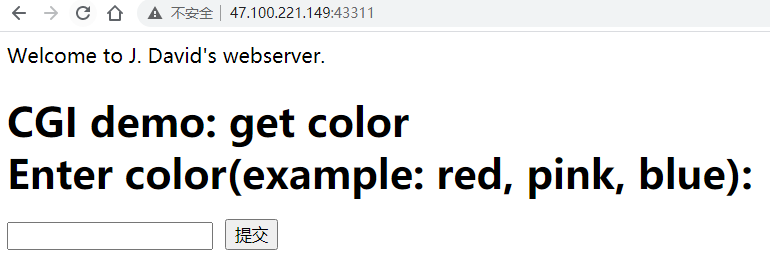
index.h调用color.cgi脚本:
<HTML>
<TITLE>Index</TITLE>
<BODY>
<P>Welcome to J. David's webserver.
<H1>CGI demo: get color
<FORM ACTION="color.cgi" METHOD="POST">
Enter color(example: red, pink, blue): <INPUT TYPE="text" NAME="color">
<INPUT TYPE="submit">
</FORM>
</BODY>
</HTML>
color.cgi内容:
#!/usr/bin/perl -Tw
use strict;
use CGI;
my($cgi) = new CGI;
print $cgi->header;
my($color) = "blue";
$color = $cgi->param('color') if defined $cgi->param('color');
print $cgi->start_html(-title => uc($color),
-BGCOLOR => $color);
print $cgi->h1("This is $color");
print $cgi->end_html;
干了两件事:
- html页面的bgcolor参数设置成了用户输入的color变量字符串
- 显示字符串:This is $color
输入“red”, 浏览器显示效果: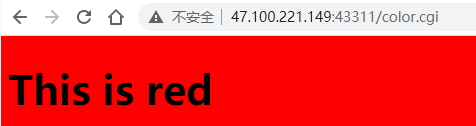
F12打开浏览器调试窗口,可见:
- 访问资源为color.cgi
- 查看http head内容,浏览器客户端的请求是POST,类型是text文本,表单数据(Form data):color的值是red
- 查看http response内容,即httpd返回的内容。返回了html文本,即浏览器可见的红色页面
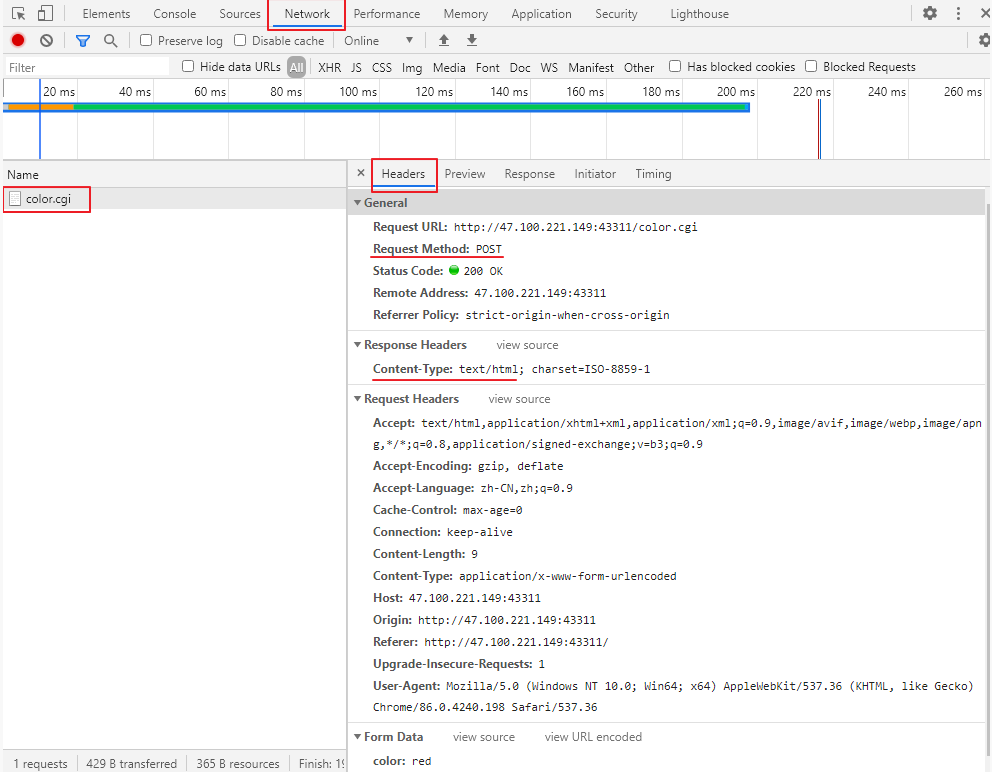
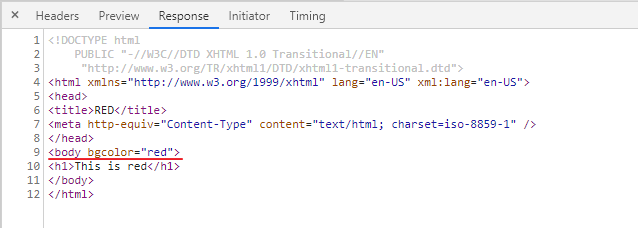
现在理解以下整个流程:
- 服务器上httpd先运行,处于监听(listen)客户端请求的状态
- 本地浏览器输入服务器ip:端口,访问httpd,发送的http请求类型是GET,即获取文本
- httpd收到请求,在处理过程中调用cgi脚本,生成response的内容
- httpd打包内容成http层的格式(head+body+…),返回浏览器客户端
- 浏览器客户端解析html文本并显示成可见的页面。
再看另外一个获取时间的功能:
浏览器输入ip:port/date.html
访问的资源是date.cgi,返回了显示当前时间的页面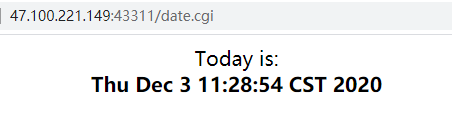
看下http请求和响应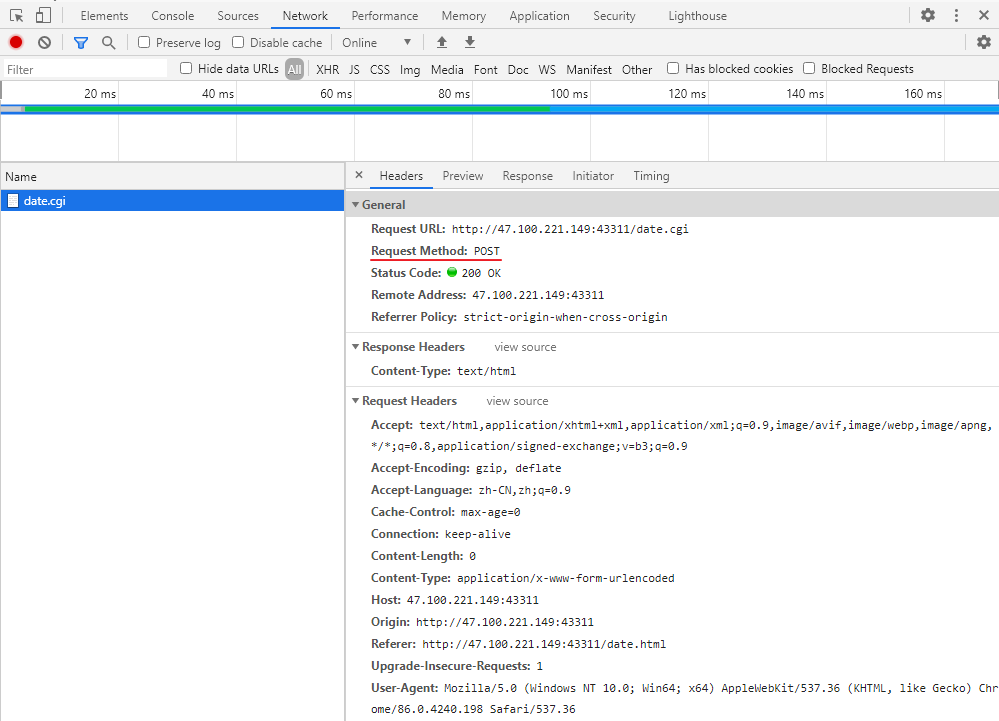
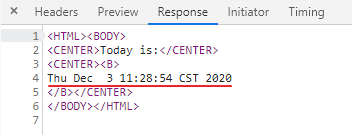
date.cgi的实现:shell直接调用linux date命令
#!/bin/bash
echo "Content-Type: text/html"
echo
echo "<HTML><BODY>"
echo "<CENTER>Today is:</CENTER>"
echo "<CENTER><B>"
date
echo "</B></CENTER>"
echo "</BODY></HTML>"
TCP socket访问httpd(测试)
client.c直接使用socket接口访问httpd,这是个测试功能,因此用编译参数控制了该功能, make test_sock=y编译该版本的httpd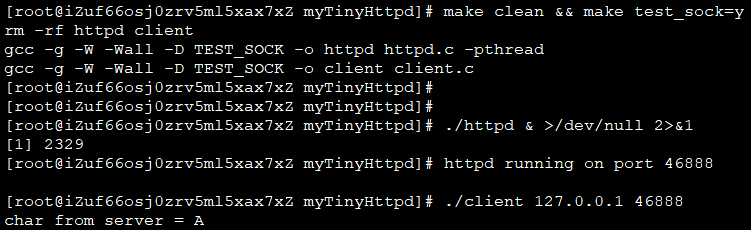
client和httpd在同一主机,直接访问回环地址127.0.0.1,可见httpd返回了client发送的字符’A’
4.源码分析
(1) httpd的处理http请求的主要流程
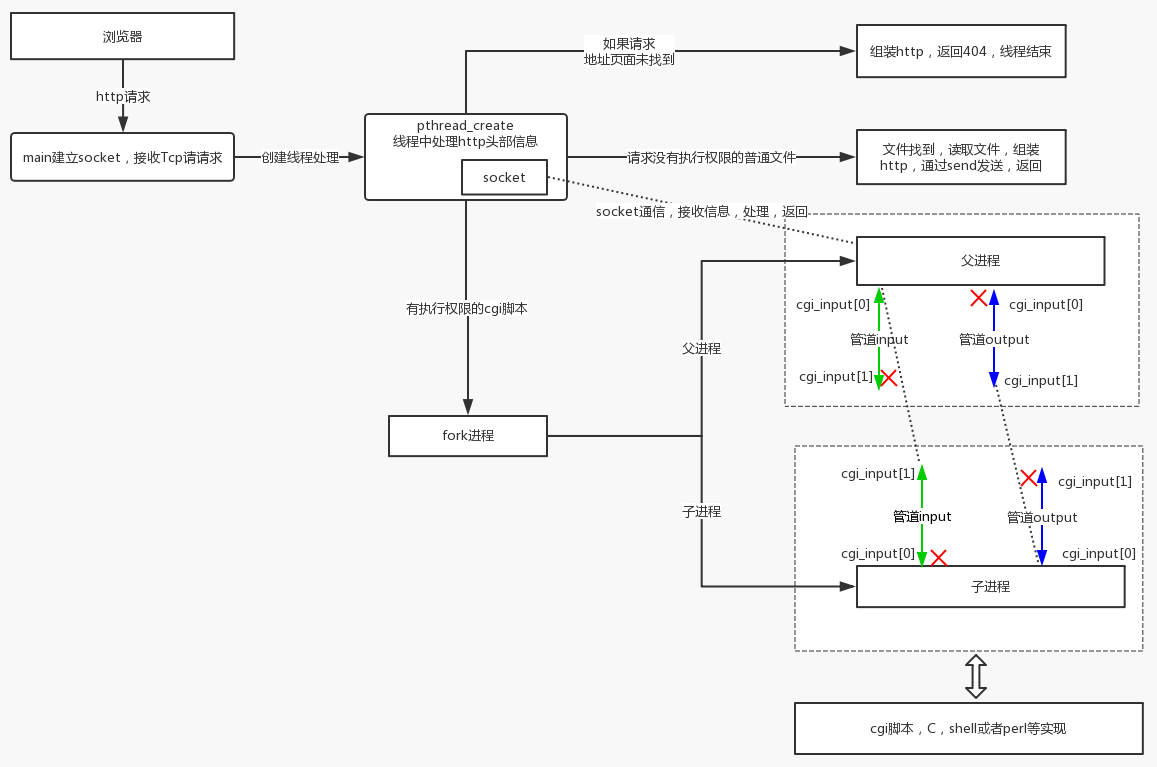
- 服务器启动,在指定端口或随机选取端口绑定 httpd 服务
- 收到一个 HTTP 请求时(其实就是 listen 的端口 accpet 的时候),派生一个线程运行 accept_request 函数
- 取出 HTTP 请求中的 method (GET 或 POST) 和 url,。对于 GET 方法,如果有携带参数,则 query_string 指针指向 url 中 ? 后面的 GET 参数
- 格式化 url 到 path 数组,表示浏览器请求的服务器文件路径,在 tinyhttpd 中服务器文件是在 htdocs 文件夹下。当 url 以 / 结尾,或 url 是个目录,则默认在 path 中加上 index.html,表示访问主页
- 如果文件路径合法,对于无参数的 GET 请求,直接输出服务器文件到浏览器,即用 HTTP 格式写到套接字上,然后跳到(10)。其他情况(带参数 GET,POST 方式,url 为可执行文件),则调用 excute_cgi 函数执行 cgi 脚本
- 读取整个 HTTP 请求并丢弃,如果是 POST 则找出 Content-Length. 把 HTTP 200 状态码写到套接字
- 建立两个管道,cgi_input 和 cgi_output, 并 fork 一个进程
- 在子进程中,把 STDOUT 重定向到 cgi_outputt 的写入端,把 STDIN 重定向到 cgi_input 的读取端,关闭 cgi_input 的写入端 和 cgi_output 的读取端,设置 request_method 的环境变量,GET 的话设置 query_string 的环境变量,POST 的话设置 content_length 的环境变量,这些环境变量都是为了给 cgi 脚本调用,接着用 execl 运行 cgi 程序
- 在父进程中,关闭 cgi_input 的读取端 和 cgi_output 的写入端,如果 POST 的话,把 POST 数据写入 cgi_input,已被重定向到 STDIN,读取 cgi_output 的管道输出到客户端,该管道输入是 STDOUT。接着关闭所有管道,等待子进程结束。管道状态参考下图。
- 关闭与浏览器的连接,完成了一次 HTTP 请求与回应, HTTP是无连接的。
管道初始状态: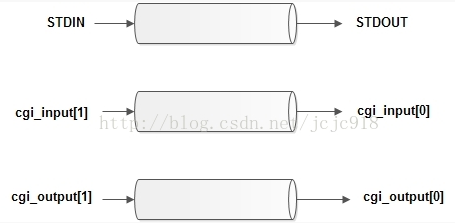
管道最终状态: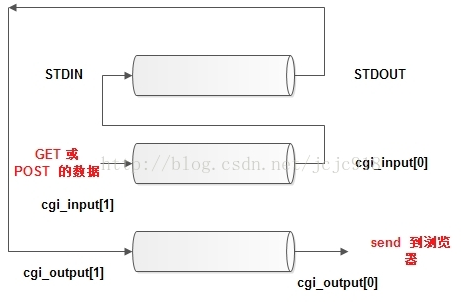
主要函数:
- startup: 初始化httpd服务,包括建立服务端的套接字,绑定端口,进行监听等
- accept_request: 处理从套接字上监听到的一个 HTTP 请求,是服务器处理请求的主流程
- execute_cgi: 运行cgi程序的处理,对应POST请求
- sever_file: 调用cat把服务器文件返回给浏览器,对应GET请求
辅助功能函数:
- get_line: 读取套接字的一行,把回车换行等情况都统一为换行符结束
- unimplemented: 返回给浏览器表明收到的HTTP请求所用的method不支持,httpd只支持GET和POST
- headers: 把HTTP响应的头部写到套接字
- cat: 读取服务器上的指定文件写到socket套接字
(2)httpd处理client的socket请求
参考TCP套接字流程,注意一点,server端回写数据后,要close掉,client才能正常close。
编译选项的实现讲一下:
Makefile根据输入参数,定义宏, 如果编译输入带参make test_sock=y,则定义宏TEST_SOCK,等价于在源码#define TEST_SOCK
#用编译选项定义宏
ifeq ($(test_sock), y)
CFLAGS+= -D TEST_SOCK
endif
httpd.c对宏的处理:
#ifdef TEST_SOCK
void test_sock(int);
#else
#define test_sock(...) do{}while(0)
#endif
这里如果没定义TEST_SOCK,直接把test_sock函数声明成do{}while(0)形式,这种控制在linux kernel源码中很常见,好处是不需要在调用处加宏控制,若TEST_SOCK未定义,调用test_sock()等价于空语句。...代表所有入参
扩展:httpd能否同时支持浏览器和client程序访问?
一个socket描述符只能对应一个客户端,如果server想要一对多的IO复用,需要select-poll机制,参考:
IO多路复用之select、poll、epoll
linux下socket编程实现一个服务器连接多个客户端