1.GDB简介
官网文档:
GDB: The GNU Project Debugger
关于GDB的原理:
GDB实现原理和使用范例
GDB工作原理和内核实现
GDB的基本工作原理
其他教程:GDB调试教程
几个重点:
- 多种运行方式:gdb启动程序再调试(独立功能程序),gdb attach进程再调试(服务端程序),gdb加载core dump调试(离线调试)
- GDB的本质是“截获”被调试程序,attach用ptrace截获了OS和应用程序之间的通信, 端点本质是trap中断,截获了CPU正常取指执行流程
本文源码:cursorhu/SimpleMultiThread/4.gdb_thread/
2.多线程程序的GDB调试
待调试代码:
#include <thread>
#include <chrono>
#include <mutex>
#include <iostream>
int g_mydata = 0;
std::mutex g_mutex;
void thread_func1()
{
while (true)
{
g_mutex.lock();
++g_mydata;
if(g_mydata == 1024)
g_mydata = 0;
g_mutex.unlock();
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
void thread_func2()
{
while (true)
{
g_mutex.lock();
std::cout << "g_mydata = " << g_mydata << ", ThreadID = " << std::this_thread::get_id() << std::endl;
g_mutex.unlock();
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
int main()
{
std::thread t1(thread_func1);
std::thread t2(thread_func2);
t1.join();
t2.join();
return 0;
}
编译:
g++ -g -std=c++11 cppthread.cpp -o cppthread -lpthread
-g: 带debug信息,gdb要用
-lpthread:链接pthread库。当应用直接调用POSIX/pthread接口,或Linux环境中运行多线程都需要
attach方式调试
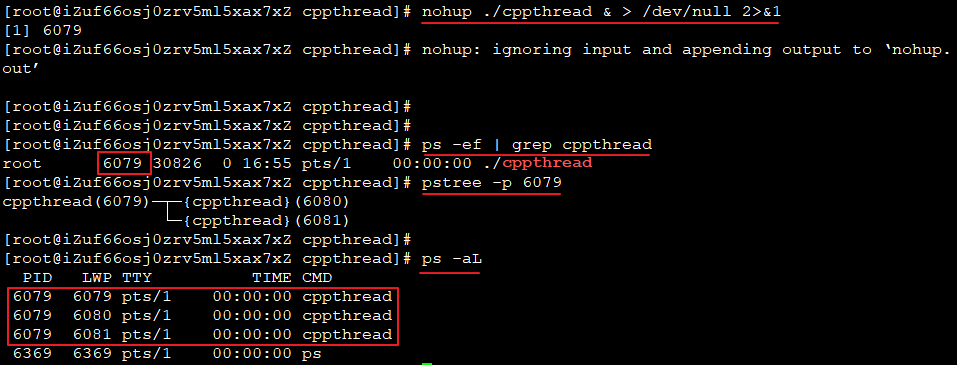
(1)后台运行并获取PID
- GDB调试已运行的程序,cppthread线程写成死循环,后台运行。
- ps -ef | grep NAME 获取PID
- pstree可以查看线程关系
- LWP:轻量级进程,是用户线程和内核的中间接口。用户级线程连接LWP上便具有内核线程的所有属性。因此可以认为LWP ID对应线程ID
(2)gdb attach,管控进程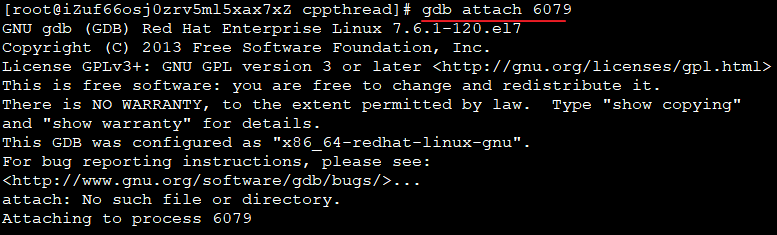
(3)查看所有线程信息
*表示当前在1号线程,注意这个ID是GDB attach后分配的,真实线程ID参考LWP
(4)查看线程backtrace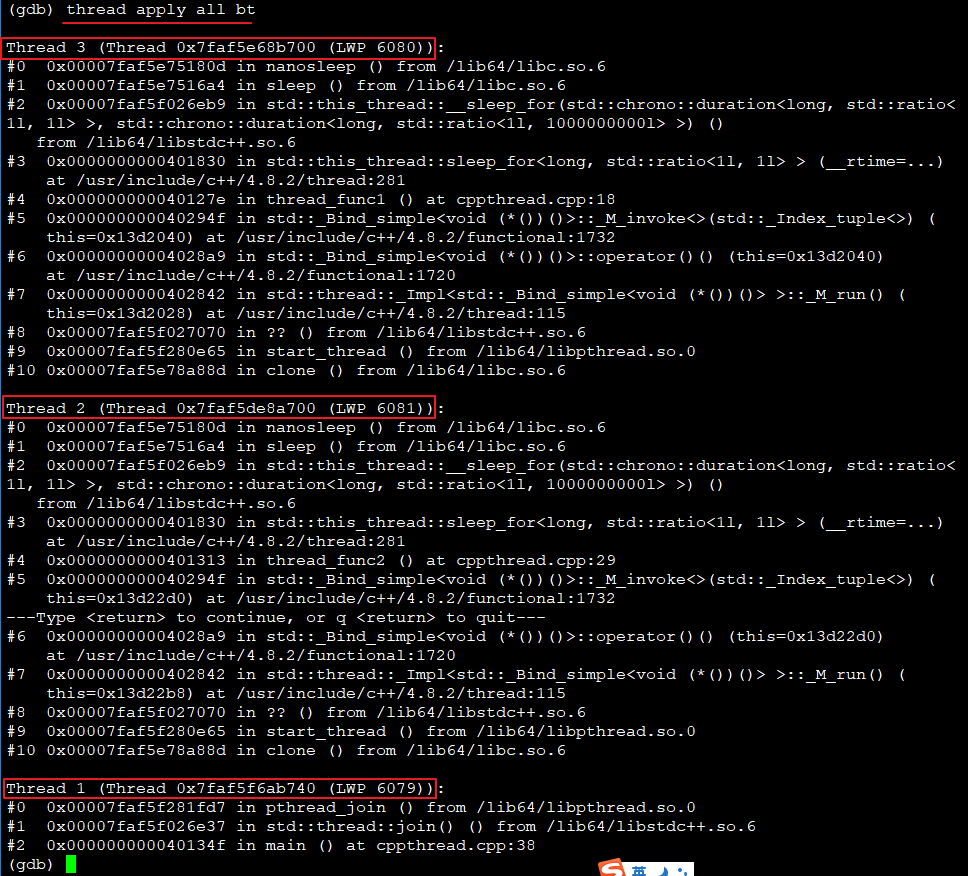
(5)切换线程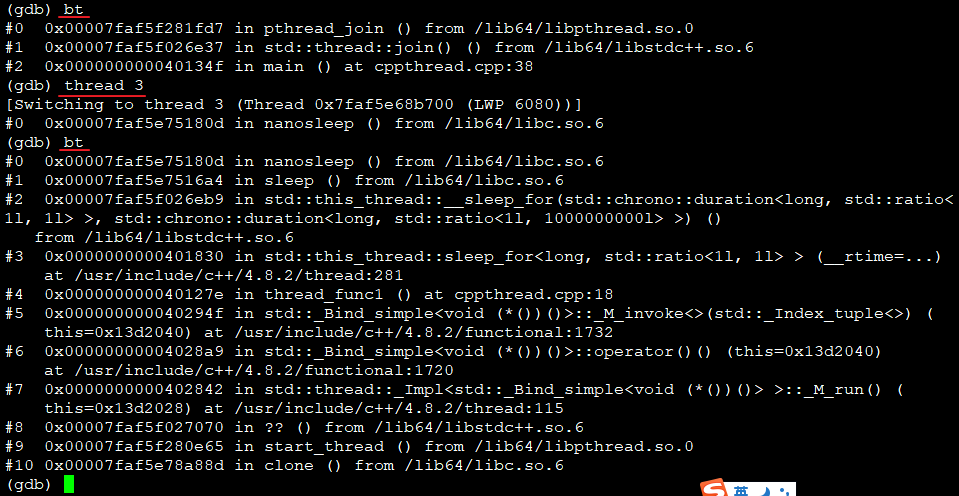
(6)单步调试线程
- 注意,GDB调试时是支持线程切换的,等同正常执行多线程,也可以禁用切换:
set scheduler-locking on。本示例有mutex锁,未见到切换 next: 单步(一步),next n: 单步n步watch 变量,可见next 6后g_mydata + 1watch会自动隐式的加断点,后文会看到断点信息
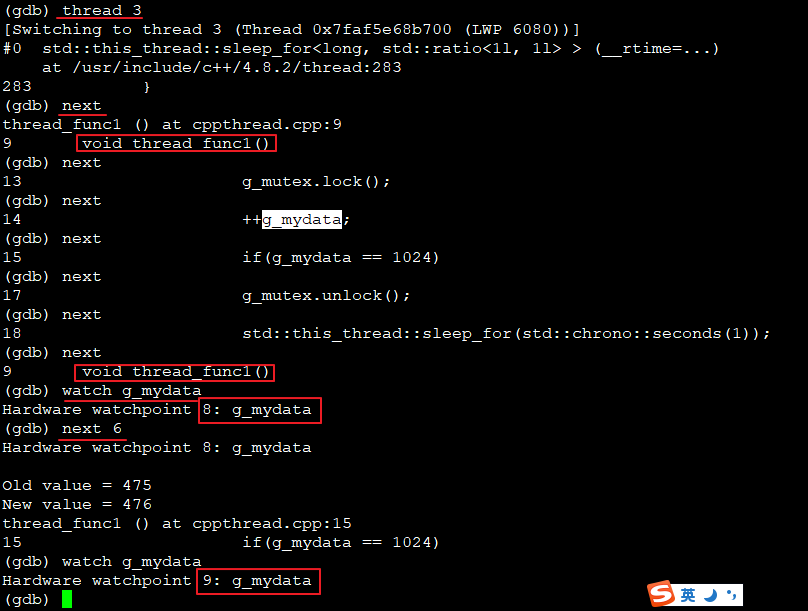
(7)断点
break i: 在代码i行加断点,break func:在函数加断点clear i: 清除i行的断点,delete id: 清除指定id的断点- 注意看watch引入了一个断点11
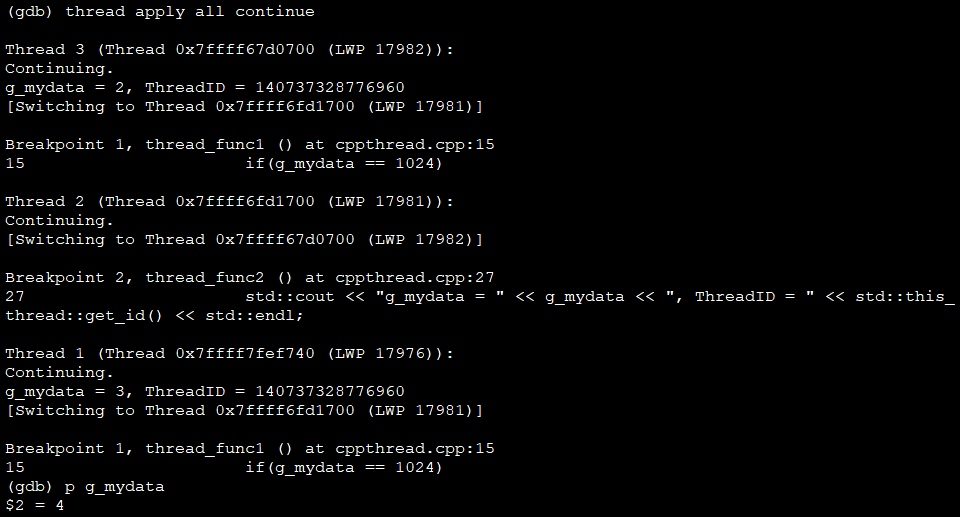
continue:继续执行,通常配合断点使用
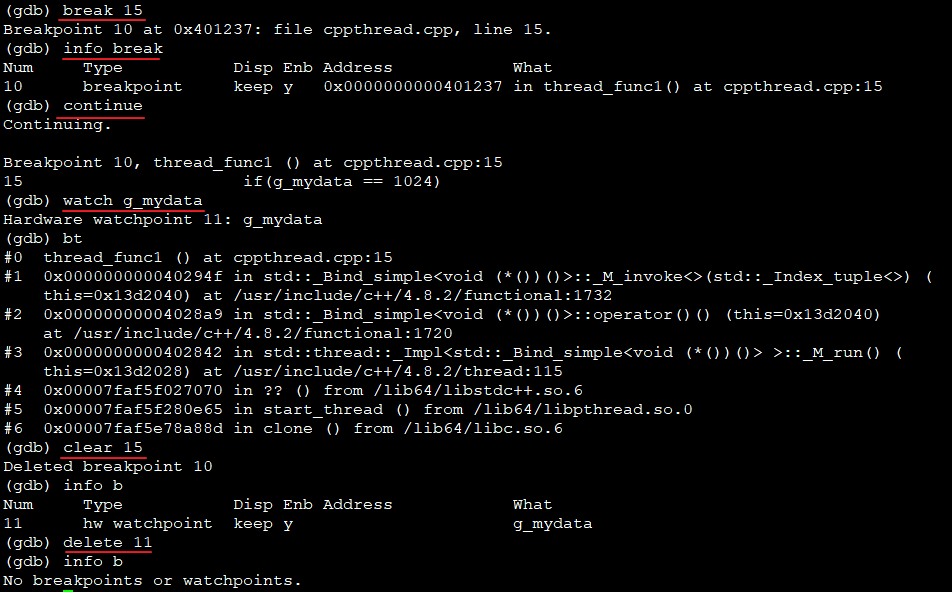
(8)线程外调试+多断点
两个工作线程都加断点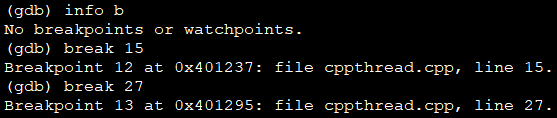
一次运行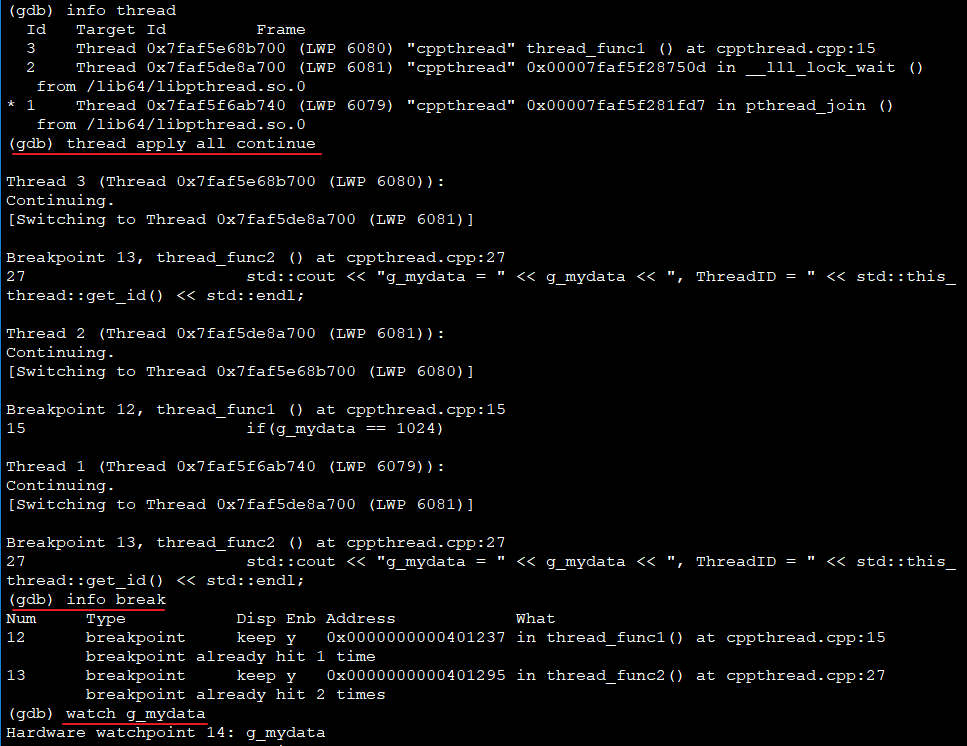
继续运行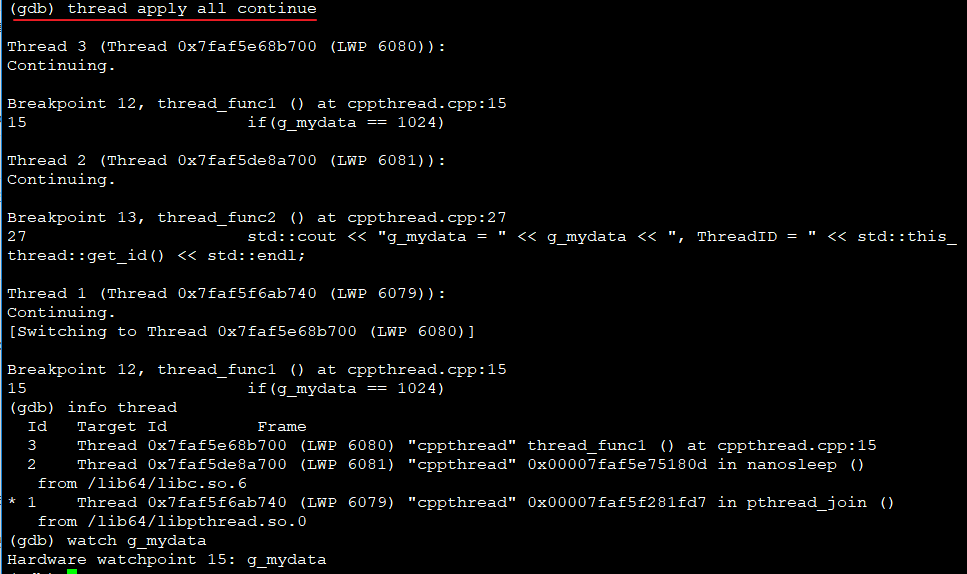
- Thread2和Thread3即工作线程,Thread1为主线程
- Thread1会切到工作线程,LWP=6080或6081
- 两次运行,Thread1切到的LWP不一样
GDB显示主线程切到哪个工作线程,实际是CPU当前在执行哪个工作线程,因此两次运行到断点时,当前执行线程分别是Thread2和Thread3,主线程实际是阻塞的。
GDB直接运行程序
用GDB运行程序的调试方式:
gdb < prog_name >
(1)运行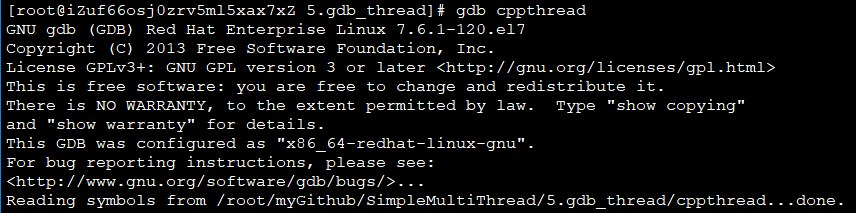
(2)加断点和执行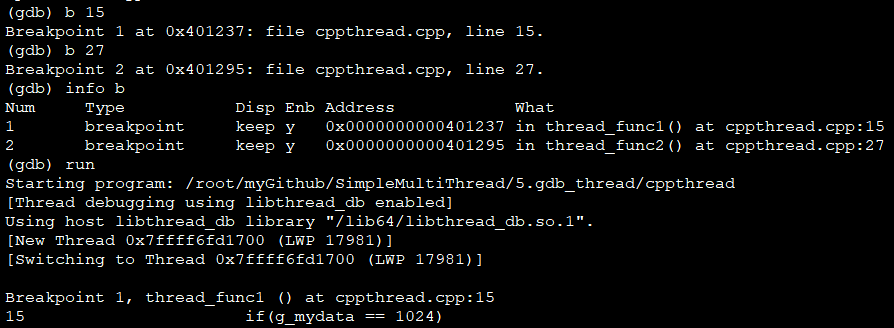
(3)查看变量值p 变量:打印变量,和watch相比不会加隐含的断点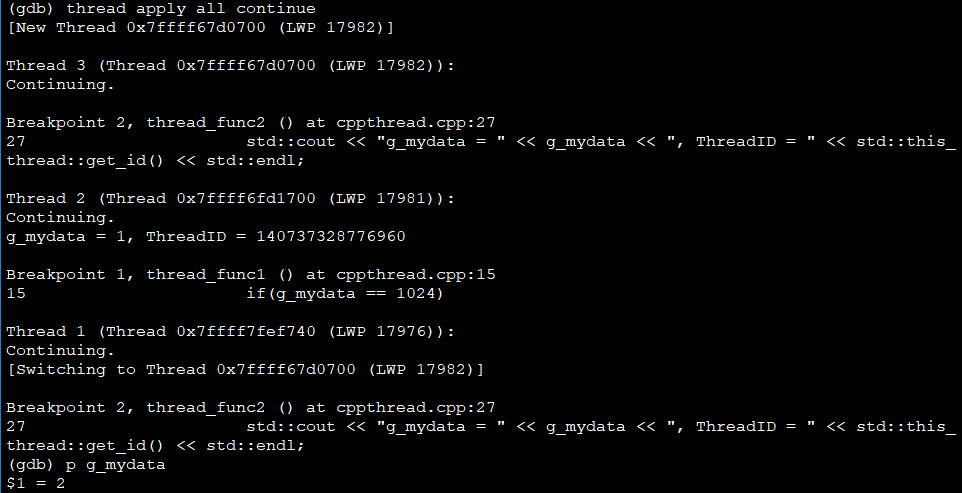
core dump文件方式调试
有关core dump
Linux 下如何产生core文件(core dump设置)
Understand and configure core dumps on Linux
C++中段错误的常见情况
coredump问题原理探究(Linux版)
下面修改前面的程序,制造core dump
(1)数组越界
cppthread_dump_array.cpp:
#include <thread>
#include <chrono>
#include <mutex>
#include <iostream>
#include <cstring>
int g_mydata = 0;
std::mutex g_mutex;
char test_dump_buf[10] = {0};
void thread_func1()
{
while (true)
{
g_mutex.lock();
++g_mydata;
char c;
sprintf(&c, "%d", g_mydata);
std::strcat(test_dump_buf, &c); //持续追加g_mydata字符串
if(g_mydata == 1024)
g_mydata = 0;
g_mutex.unlock();
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
void thread_func2()
{
while (true)
{
g_mutex.lock();
std::cout << "g_mydata = " << g_mydata << ", ThreadID = " << std::this_thread::get_id() << std::endl;
std::cout << "test_dump_buf: " << test_dump_buf << std::endl;
g_mutex.unlock();
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
int main()
{
std::thread t1(thread_func1);
std::thread t2(thread_func2);
t1.join();
t2.join();
return 0;
}
运行结果: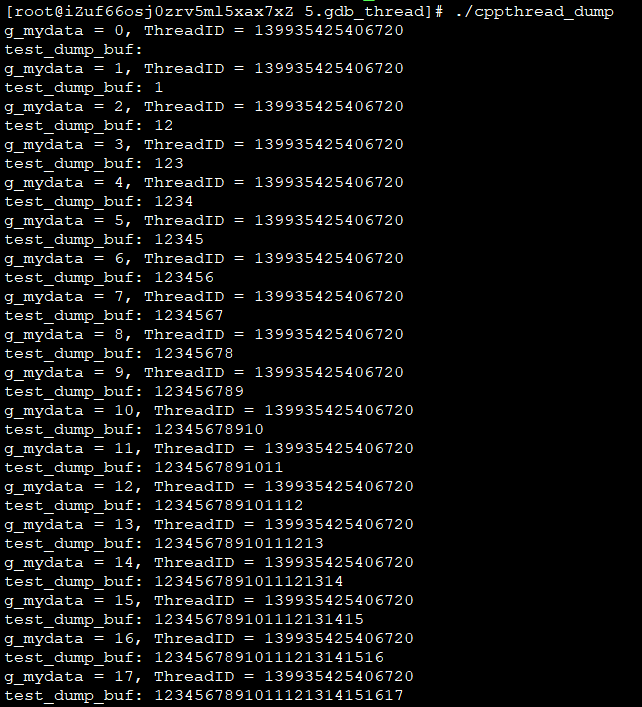
并未发生段错误,更不谈core dump。因为CPP对数组没有越界限制,这是个“合法”行为
(2)使用空指针
cppthread_dump_nullptr.cpp:
#include <thread>
#include <chrono>
#include <mutex>
#include <iostream>
#include <unistd.h> //for linux sleep()
std::mutex g_mutex;
class Foo
{
public:
Foo(int m)
{
m_data = m;
}
~Foo(){}
void printval()
{
std::cout << "m_data = " << m_data << std::endl;
}
void increase()
{
++m_data;
}
int getval()
{
return m_data;
}
void resetval()
{
m_data = 0;
}
private:
int m_data;
};
void thread_func1(Foo& p)
{
while (true)
{
g_mutex.lock();
p.increase();
if(p.getval() == 1024)
p.resetval();
g_mutex.unlock();
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
void thread_func2(Foo& p)
{
while (true)
{
g_mutex.lock();
p.printval();
g_mutex.unlock();
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
int main()
{
Foo *pFoo = new Foo(0);
std::thread t1(thread_func1, std::ref(*pFoo)); //std::ref用于std::thread传入参数,以引用的形式
std::thread t2(thread_func2, std::ref(*pFoo));
//t1.join(); //这里故意不join
//t2.join();
sleep(10); //sleep等一下thread1,2
delete pFoo;
pFoo = NULL; //这时thread1,2还没执行完,形成了使用空指针的条件
return 0;
}
运行结果: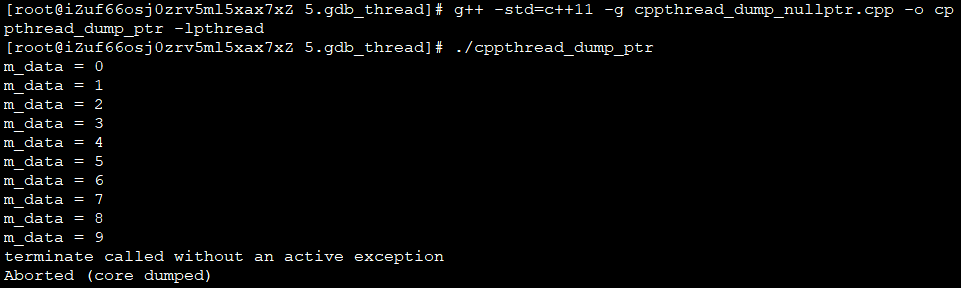
下面gdb调试这个core dump
设置core dump文件大小限制为不受限
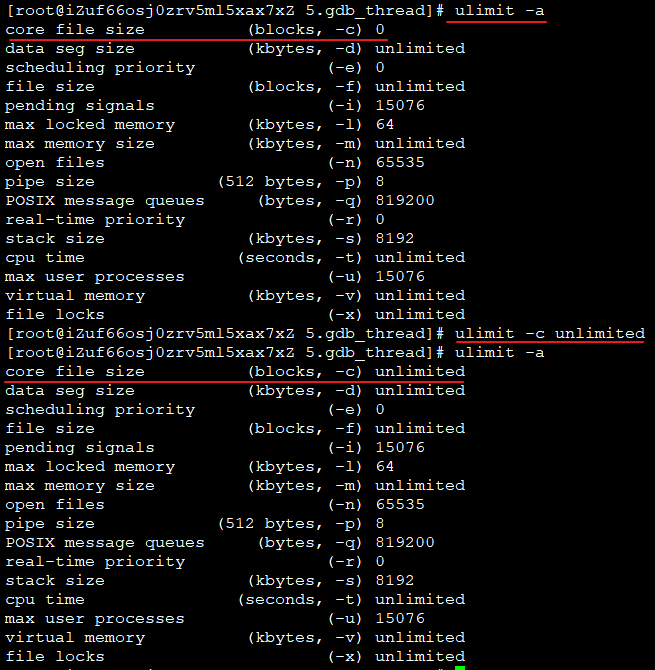
最好写入配置文件
gdb加载程序和core dump文件
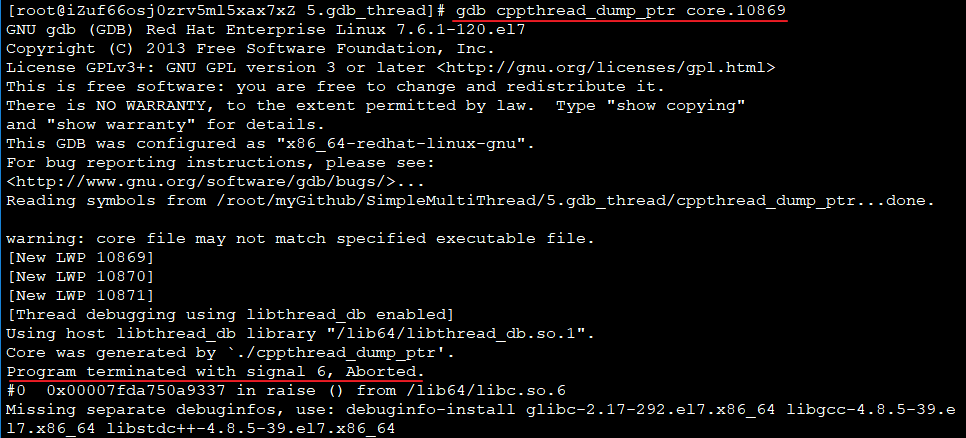
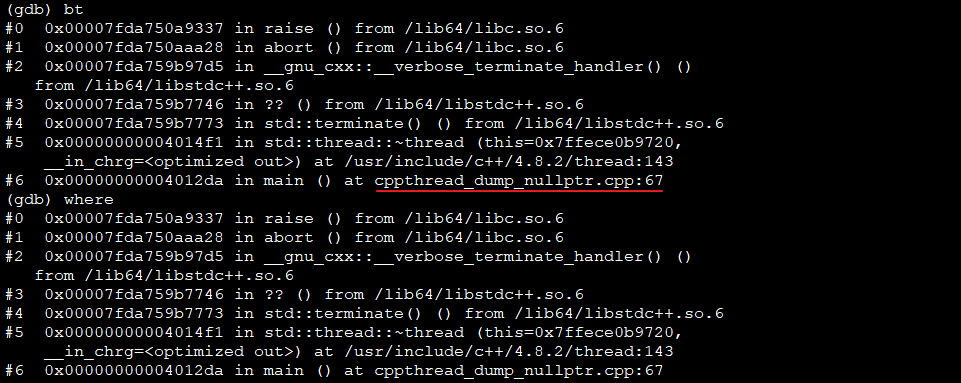
可见siganl 6发生,使进程终止看dump位置,bt或where都可以
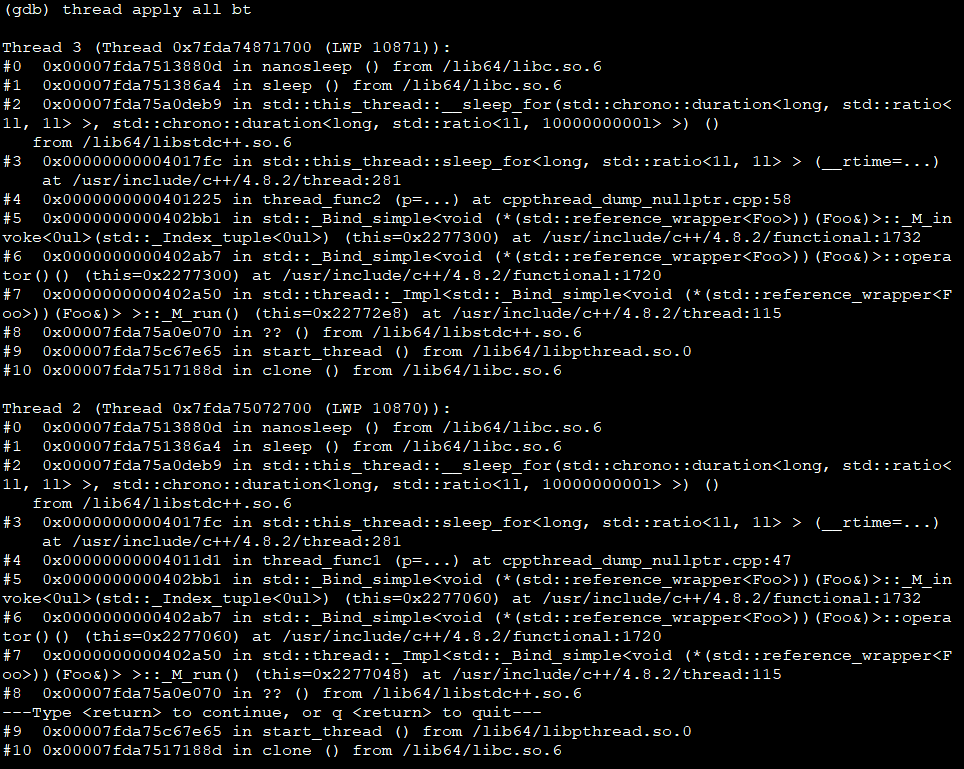
看所有线程的栈
直接看dump附近的代码
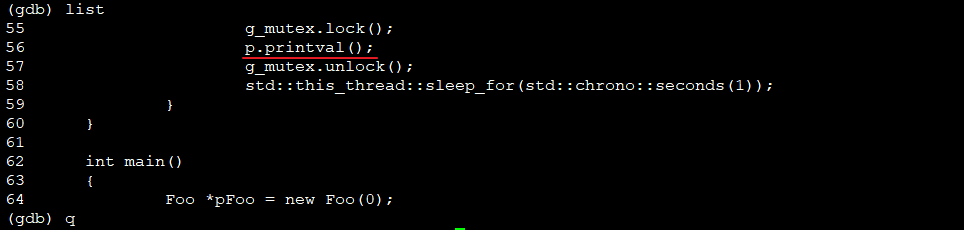
结论:根据bt/where, dump发生时,主进程在在执行67行:
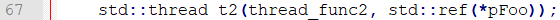
根据源码,具体是工作线程调用对象的方法时发生
再看dump打印,正好要打印m_data = 10的时候dump,结合main中sleep(10)和工作线程sleep(1),dump原因是main把对象指针置空了,而两个工作线程还在调用对象的方法,位置是thread_func2的p.printval()处
一个示例:调试死锁
最常见的死锁是双重加锁,和双重delete的道理一样,代码复杂了,层层调用的情况下容易出现
示例代码cppthread_deadlock.cpp:
线程函数和其调用的类方法都加锁了,形成死锁
#include <thread>
#include <chrono>
#include <mutex>
#include <iostream>
#include <unistd.h> //for linux sleep()
std::mutex g_mutex;
class Foo
{
public:
Foo(int m)
{
m_data = m;
}
~Foo(){}
void printval()
{
std::cout << "m_data = " << m_data << std::endl;
}
void increase()
{
g_mutex.lock(); //故意制造双重加锁
++m_data;
g_mutex.unlock();
}
int getval()
{
return m_data;
}
void resetval()
{
m_data = 0;
}
private:
int m_data;
};
void thread_func1(Foo& p)
{
while (true)
{
g_mutex.lock();
p.increase();
if(p.getval() == 1024)
p.resetval();
g_mutex.unlock();
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
void thread_func2(Foo& p)
{
while (true)
{
g_mutex.lock();
p.printval();
g_mutex.unlock();
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
int main()
{
Foo *pFoo = new Foo(0);
std::thread t1(thread_func1, std::ref(*pFoo)); //std::ref用于std::thread传入参数,以引用的形式
std::thread t2(thread_func2, std::ref(*pFoo));
t1.join();
t2.join();
delete pFoo;
pFoo = NULL;
return 0;
}
调试:
- 直接运行方式,要run起来才有线程
- backtrace可见两个线程都停止于lock_wait(),其中thread2回溯看到死锁代码在45行
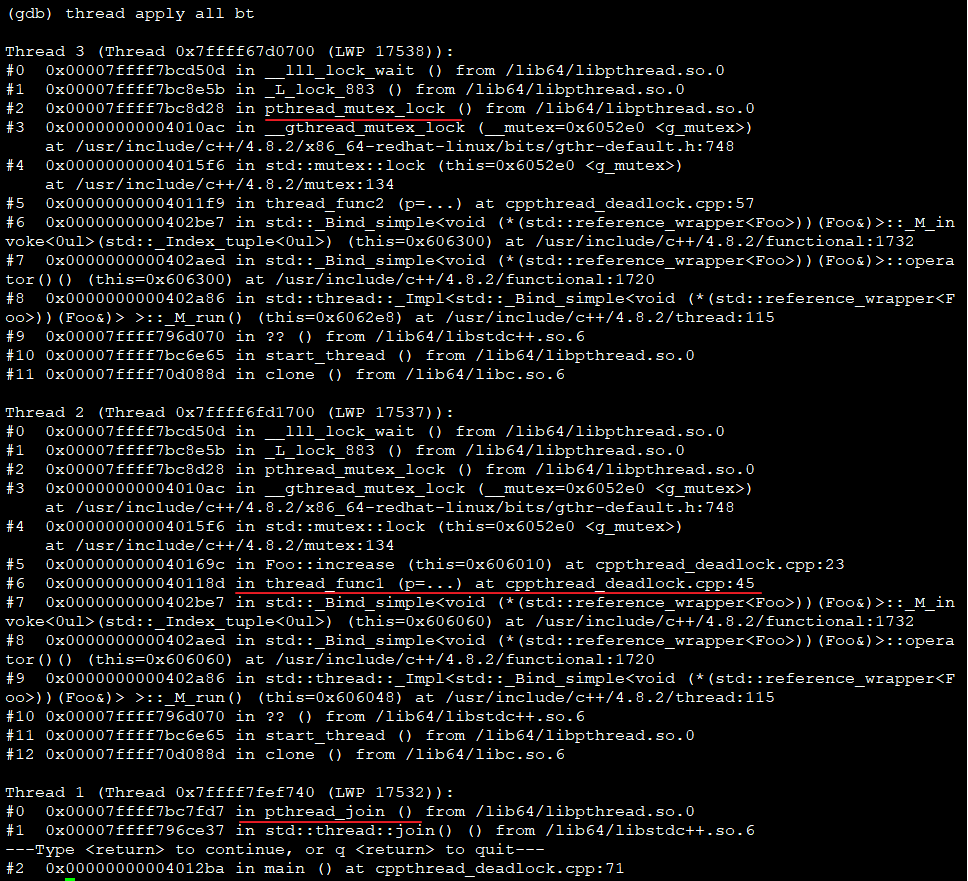
对于互斥锁推荐用RAII机制的std::lock_guard<mutex> lockGuard(m),能避免忘记unlock情况。但在此示例中,lock_guard也会双重加锁。